EfficientLLM:
Efficiency in Large Language Models
Our Framework
"The first rule of any technology used in a business is that automation applied to an efficient operation will magnify the efficiency. The second is that automation applied to an inefficient operation will magnify the inefficiency."
EfficientLLM establishes a comprehensive benchmark to evaluate and compare efficiency techniques across the lifecycle of large language models—from architecture pretraining to fine-tuning and inference—providing actionable insights into trade-offs between performance and consumption.
Ranking
| Category | Method | Performance | Utilization | Latency | Throughput | Energy | Compression | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| AMU | PCU | AL | TT | ST | IT | AEC | MCR | ||||
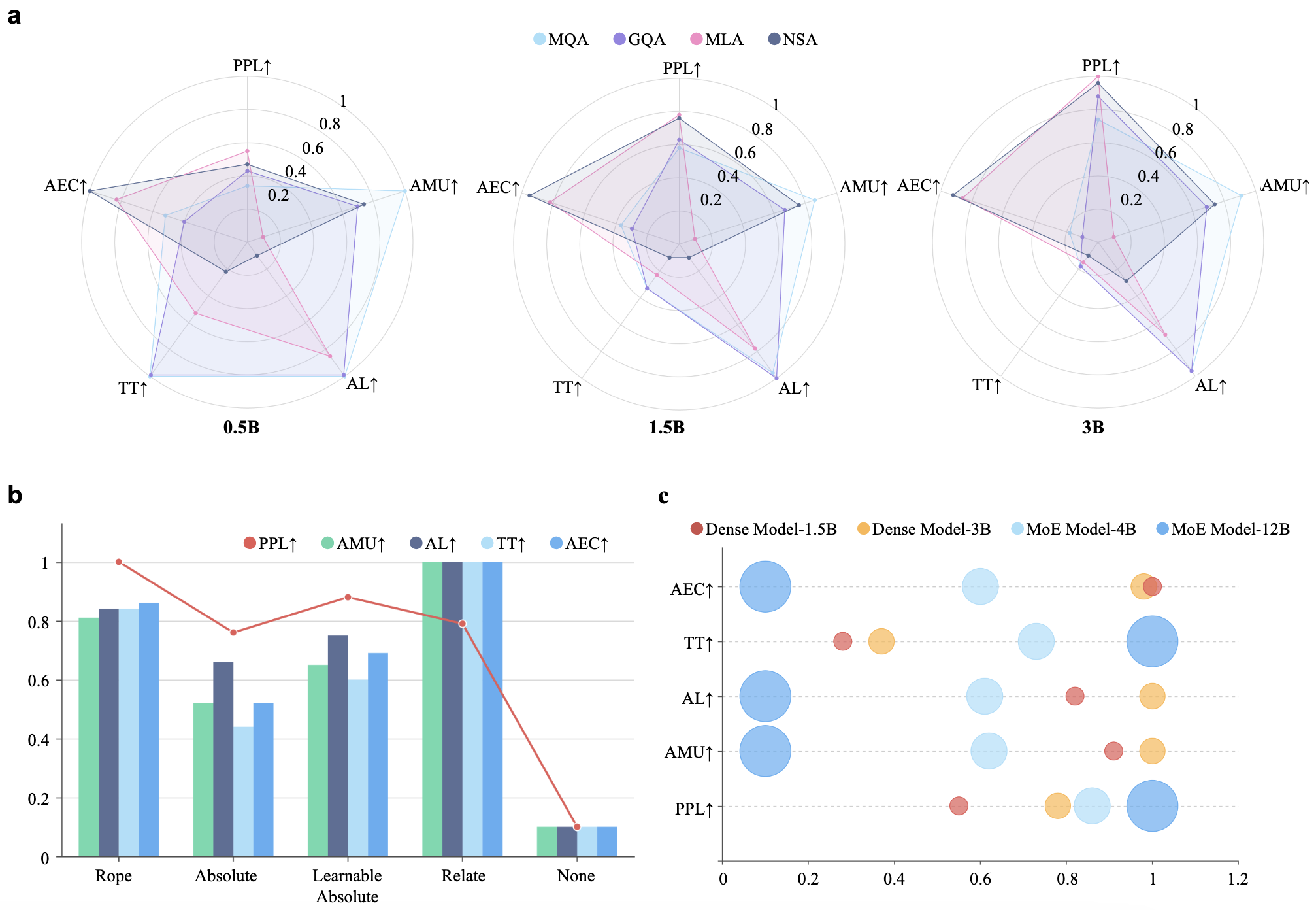
| Architecture Pretraining Efficiency | Attention Mechanism | MQA | 4 | 1 | 1 | 1 | 2 | 2 | 3 | ||
| GQA | 3 | 3 | 2 | 2 | 2 | 2 | 4 | ||||
| MLA | 1 | 4 | 3 | 3 | 2 | 2 | 2 | ||||
| NSA | 2 | 2 | 4 | 4 | 2 | 2 | 1 | ||||
| Efficient Positional Encoding | RoPE | 1 | 2 | 2 | 2 | 2 | 2 | 2 | |||
| Absolute | 4 | 4 | 4 | 4 | 2 | 2 | 4 | ||||
| Learnable Absolute | 2 | 3 | 3 | 3 | 2 | 2 | 3 | ||||
| Relate | 3 | 1 | 1 | 1 | 2 | 2 | 1 | ||||
| MoE Mechanism | Dense Model 1.5B | 4 | 2 | 2 | 3 | 2 | 2 | 2 | |||
| Dense Model 3B | 3 | 1 | 1 | 4 | 2 | 2 | 1 | ||||
| MoE Model 1.5Bx8 | 1 | 4 | 4 | 1 | 2 | 2 | 4 | ||||
| MoE Model 0.5Bx8 | 2 | 3 | 3 | 2 | 2 | 2 | 3 | ||||
| Attention-free Mechanism | Transformer | 1 | 4 | 4 | 1 | 2 | 2 | 4 | |||
| Mamba | 2 | 1 | 1 | 4 | 2 | 2 | 1 | ||||
| Pythia | 4 | 3 | 3 | 3 | 2 | 2 | 3 | ||||
| RWKV | 3 | 2 | 2 | 2 | 2 | 2 | 2 | ||||
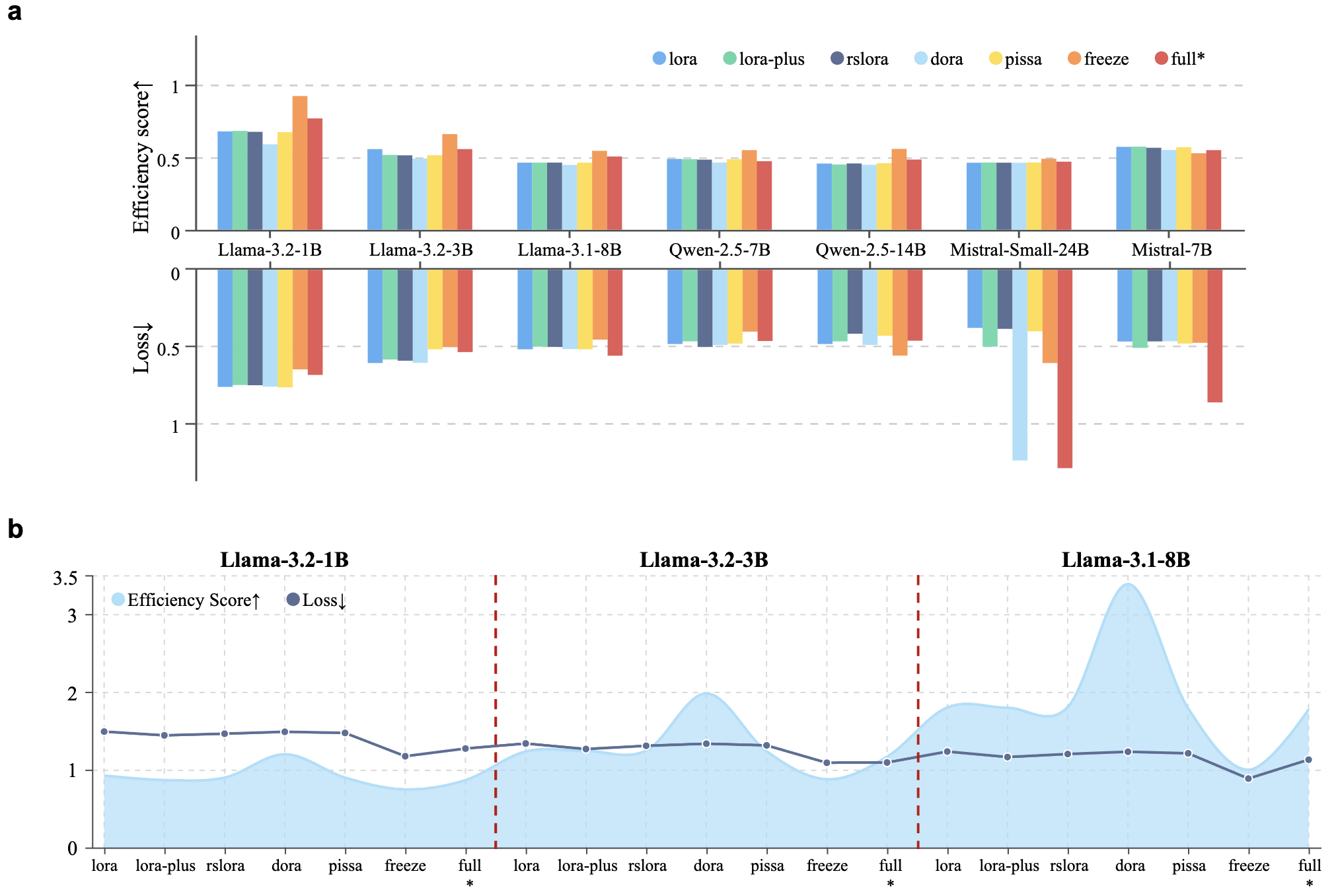
| Training & Tuning Efficiency | 1B-3B | LoRA | 7 | 2 | 2 | 3 | 2 | 3 | |||
| LoRA-Plus | 4 | 5 | 6 | 4 | 3 | 2 | |||||
| RSLoRA | 5 | 4 | 5 | 5 | 4 | 5 | |||||
| DoRA | 6 | 7 | 3 | 7 | 6 | 6 | |||||
| PiSSA | 3 | 6 | 4 | 6 | 5 | 4 | |||||
| Freeze | 1 | 3 | 7 | 1 | 7 | 1 | |||||
| Full* | 2 | 1 | 1 | 2 | 1 | 7 | |||||
| 7B-8B | LoRA | 2 | 1 | 5 | 5 | 4 | 3 | ||||
| LoRA-Plus | 5 | 2 | 7 | 6 | 5 | 2 | |||||
| RSLoRA | 3 | 4 | 6 | 3 | 3 | 5 | |||||
| DoRA | 4 | 6 | 3 | 7 | 7 | 6 | |||||
| PiSSA | 6 | 3 | 4 | 4 | 5 | 4 | |||||
| Freeze | 1 | 7 | 2 | 1 | 1 | 1 | |||||
| Full* | 7 | 5 | 1 | 2 | 2 | 7 | |||||
| 14B-24B | LoRA | 3 | 1 | 6 | 2 | 3 | 6 | ||||
| LoRA-Plus | 4 | 3 | 7 | 6 | 7 | 1 | |||||
| RSLoRA | 1 | 2 | 5 | 4 | 4 | 5 | |||||
| DoRA | 6 | 7 | 3 | 7 | 2 | 4 | |||||
| PiSSA | 2 | 4 | 4 | 3 | 4 | 3 | |||||
| Freeze | 5 | 6 | 2 | 1 | 1 | 2 | |||||
| Full* | 7 | 5 | 1 | 5 | 6 | 7 | |||||
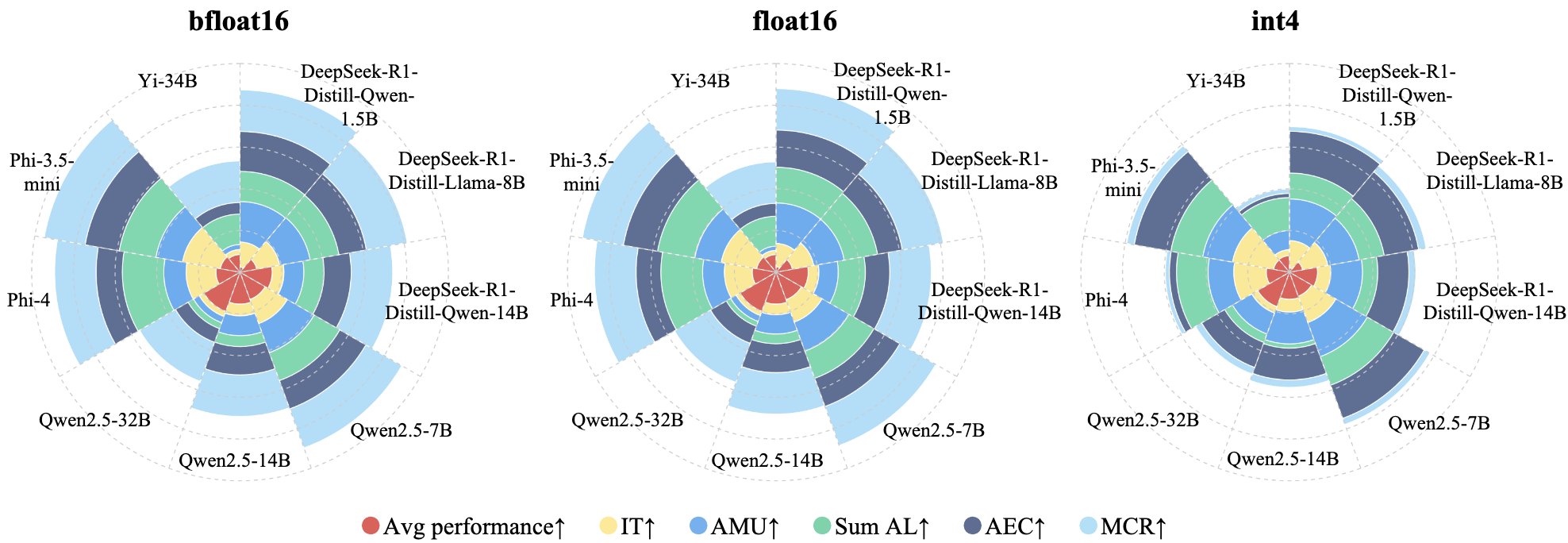
| Bit-Width Quantization | 1.5B-3.8B | bfloat16 | 1 | 2 | 2 | 2 | 2 | 2 | 3 | ||
| float16 | 1 | 3 | 2 | 1 | 3 | 3 | 2 | ||||
| int4 | 3 | 1 | 2 | 3 | 1 | 1 | 1 | ||||
| 7B-8B | bfloat16 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | |||
| float16 | 2 | 3 | 2 | 1 | 3 | 3 | 3 | ||||
| int4 | 3 | 1 | 2 | 3 | 1 | 1 | 1 | ||||
| 14B-34B | bfloat16 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | |||
| float16 | 2 | 3 | 2 | 1 | 3 | 1 | 3 | ||||
| int4 | 3 | 1 | 2 | 3 | 1 | 3 | 1 | ||||
Legend: (Color mapping for scores across categories)
High Tier - (e.g., Arch: 1; Training: 1-2; Quant: 1)
Medium Tier - (e.g., Arch: 2-3; Training: 3-5; Quant: 2)
Low Tier - (e.g., Arch: 4; Training: 6-7; Quant: 3)
Metrics:
AMU - Accelerator Memory Utilization | PCU - Processor Compute Utilization | AL - Average Latency | TT - Training Throughput | ST - Serving Throughput | IT - Inference Throughput | AEC - Average Energy Consumption | MCR - Model Compression Ratio
Architecture Pretraining Efficiency
All values presented in our figures are min-max normalized within each metric across all models. For consistency, all metrics (e.g., PPL, FID, and etc.) are transformed such that higher values indicate better performance or efficiency.
Training and Tuning Efficiency
Bit-Width Quantization Efficiency